Метод главных компонент (PCA)
Введение
Часто n-мерное пространство признаков оказывается избыточным. Объекты (точки) концентрируются в нём на вложенных m-мерных поверхностях, где m существенно меньше n. Выявление таких поверхностей приводит к снижению размерности задачи и упрощению дальнейшего анализа данных (в задачах классификации и т.п.). Метод главных компонент (principal component analysis) является простейшим методом, в котором, в качестве m-мерной поверхности выступает m-плоскость.
Напомним, что m векторов ek={e1,...,em} задают уравнение m-плоскости в n-мерном пространстве: x=x0+m∑k=1tkek. Параметры {t1,...,tm} выступают декартовыми координатами в базисе {e1,...,em} (если он ортогонален). Вектор x0 задаёт положение начала координат (точка в которой все координаты на плоскости tk равны нулю). Если m=1, то (1) будет уравнением прямой (одномерный объект). При m=2 мы имеем двумерную плоскость и т.д.
Квадрат кратчайшего евклидового расстояния d2=(X−x)2 от произвольной точки X до m-плоскости (1) равно d2=(X−x0)2−m∑k=1[(X−x0)ek]2, а проекция точки X на m-плоскости имеет следующие координаты (в n- и m- пространствах): X ↦ x=x0+m∑k=1[(X−x0)ek]ek, tk=(X−x0)ek.
Центр тяжести
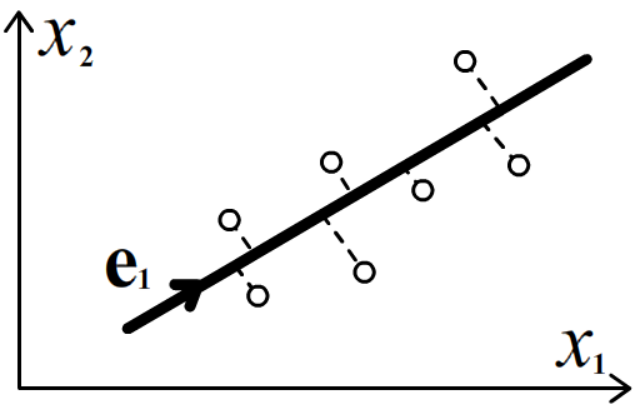 В методе главных компонент ищут m-плоскость, сумма квадратов расстояний от которой до
множества точек (обучающий набор объектов) X1,...,XN минимальна (нижний индекс - номер объекта).
Будем в дальнейшем обозначать угловыми скобками усреднение по всем точкам.
Например, среднее значение (центр тяжести N объектов)
равен:
⟨X⟩=1NN∑i=1Xi.
Таким образом, мы требуем, чтобы
⟨d2⟩=⟨(X−x0)2⟩−m∑k=1⟨[(X−x0)ek]2⟩=min.
Определим сначала x0. Беря производную по x0 и приравнивая её нулю, имеем:
⟨X−x0⟩−m∑k=1[(⟨X⟩−x0)ek]ek=0.
Это соотношение тождественно выполняется, если x0=⟨X⟩, т.е. плоскость
проходит через центр тяжести.
Поэтому вычтем его из каждой точки: Xi↦Xi−⟨X⟩
и далее будем считать, что ⟨X⟩=0 и x0=0.
В методе главных компонент ищут m-плоскость, сумма квадратов расстояний от которой до
множества точек (обучающий набор объектов) X1,...,XN минимальна (нижний индекс - номер объекта).
Будем в дальнейшем обозначать угловыми скобками усреднение по всем точкам.
Например, среднее значение (центр тяжести N объектов)
равен:
⟨X⟩=1NN∑i=1Xi.
Таким образом, мы требуем, чтобы
⟨d2⟩=⟨(X−x0)2⟩−m∑k=1⟨[(X−x0)ek]2⟩=min.
Определим сначала x0. Беря производную по x0 и приравнивая её нулю, имеем:
⟨X−x0⟩−m∑k=1[(⟨X⟩−x0)ek]ek=0.
Это соотношение тождественно выполняется, если x0=⟨X⟩, т.е. плоскость
проходит через центр тяжести.
Поэтому вычтем его из каждой точки: Xi↦Xi−⟨X⟩
и далее будем считать, что ⟨X⟩=0 и x0=0.
Первый компонент
Для определения направляющих векторов e1,...,em (базис в плоскости) необходимо найти максимум (знак минус в (2)!) выражения: D=m∑k=1⟨(Xek)2⟩=⟨(Xe1)2⟩+...+⟨(Xem)2⟩=max, ekep=δkp, при сохранении ортонормированности векторов. Максимальным должно быть каждое слагаемое в сумме. Чем больше значение слагаемого, тем более значимым является k-й вектор. Пусть эти слагаемые отсортированы по убыванию значимости. Определим сначала e1, который называют первым компонентом. В плоскости он может иметь произвольное направление (произвол ориентации базиса в плоскости). Поэтому стоит задача поиска максимума ⟨(Xe1)2⟩ при условии, что e21=1. Эту задачу можно решать методом множителей Лагранжа: ⟨(Xe1)2⟩+λ(1−e21)=max. Беря производные по e1, λ и приравнивая их нулю, имеем: ⟨(Xe1)X⟩=λe1, e21=1. Обозначим в круглых скобках номер компоненты вектора в n-мерном пространстве: e1={e(1)1,...,e(n)1}. Первое уравнение переписывается в форме уравнения на собственные значения: n∑j=1Cije(j)1=λe(i)1 ковариационной матрицы: Cij=⟨X(i)X(j)⟩=1N−1N∑k=1X(i)kX(j)k.
Из (6) следует (умножаем первое соотношение на e1), что λ=⟨(Xe1)2⟩, поэтому из всех собственных значений необходимо выбрать максимальное. Впрочем, это не обязательно. Если будут найдены все собственные значения матрицы Cij (см. ниже), то их можно отсортировать в порядке убывания, оставив только m самых больших. Соответствующие им собственные векторы ковариационной матрицы и являются искомыми направляющими векторами m-плоскости.
Второй компонент
Пусть первый компонент e1 и первое собственное значение λ1=λ матрицы Cij уже найдены. Изменим координаты точек следующущим образом: X′=X−(Xe1)e1, X′e1=0. Среднее значение останется нулевым ⟨X′⟩=0. Остаток максимизируемой суммы (4) также не поменяется: D′=⟨(Xe2)2⟩+...+⟨(Xem)2⟩=⟨(X′e2)2⟩+...+⟨(X′em)2⟩=max. Его необходимо продолжать максимизировать. Заметим, что пересчитывать ковариационную матрицу (8) по всем точкам X′ не обязательно, так после преобразования (9) она меняется следующим образом: C′ij=Cij−n∑k=1Ckie(k)1e(j)1−n∑k=1Ckje(k)1e(i)1+n∑k=1Ckpe(k)1e(p)1e(i)1e(j)1. Учитывая уравнение на собственные значения (7) это соотношение можно упростить: C′ij=Cij−λ1e(i)1e(j)1. Теперь процесс поиска максимума можно повторять до тех пор, пока все векторы базиса плоскости не будут найдены. При этом, в силу построения по формуле (9), все эти векторы окажутся ортогональными.
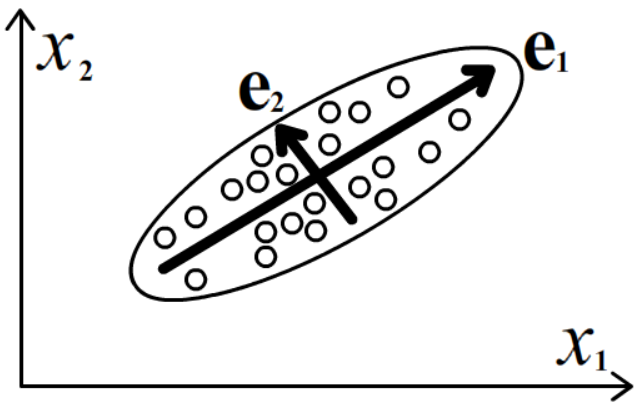 Несложно видеть, собственные значения матрицы C′ij одновременно являются
собственными значениями исходной матрицы Cij.
Поэтому m-плоскость строиться по m собственным векторами ковариационной матрицы, соответствующим максимальным
собственным значениям.
Несложно видеть, собственные значения матрицы C′ij одновременно являются
собственными значениями исходной матрицы Cij.
Поэтому m-плоскость строиться по m собственным векторами ковариационной матрицы, соответствующим максимальным
собственным значениям.
Ещё одна интерпретация собственных векторов ковариационной матрицы - это оси эллипсоида характерного "разброса" точек в пространстве. Если эллипсоид вытянут вдоль одной из осей - это главная (наиболее значимая) компонента. Следующая по "вытянутости" ось - вторая компонента и т.д.
Пример 1: ирисы Фишера
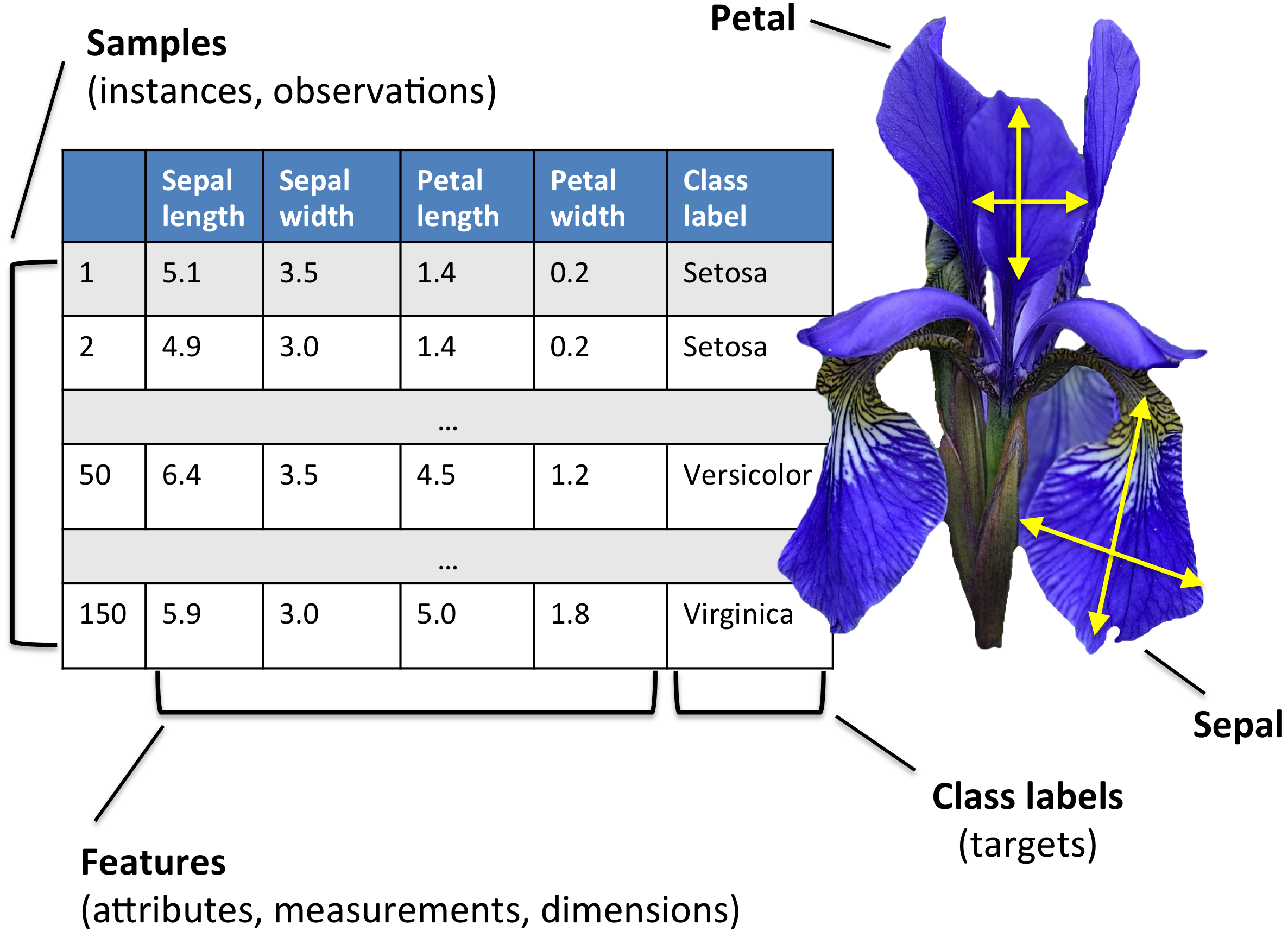 Рассмотрим в качестве примера набор из 150 измерений длины и ширины лепестков цветков ириса (ирисы Фишера).
В данном случае пространство признаков 4-мерно и в задаче классификации присутствуют 3 класса.
Рассмотрим в качестве примера набор из 150 измерений длины и ширины лепестков цветков ириса (ирисы Фишера).
В данном случае пространство признаков 4-мерно и в задаче классификации присутствуют 3 класса.
Статистики по всем признакам имеют вид:
xi aver sigma min max x1 5.843 0.828 4.30 7.90 x2 3.054 0.434 2.00 4.40 x3 3.759 1.764 1.00 6.90 x4 1.199 0.763 0.10 2.50После нормировки xi↦(xi−⟨xi⟩)/σi ковариационная матрица Cij равна:
1.000 -0.109 0.872 0.818 -0.109 1.000 -0.421 -0.357 0.872 -0.421 1.000 0.963 0.818 -0.357 0.963 1.000Её собственные значения и собственные векторы:
λ1=2.911; e1=(-0.522, 0.263, -0.581, -0.566) λ2=0.921; e2=(-0.372, -0.926, -0.021, -0.065) λ3=0.147; e3=( 0.721, -0.242, -0.141, -0.634) λ4=0.021; e4=(-0.262, 0.124, 0.801, -0.524)
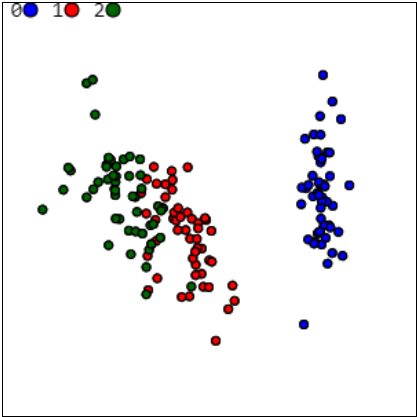 Главная компонента (наибольшее собственное значение λ1=2.911) cущественно отличается
от остальных. Это свидетельствует о том, что точки в 4-мерном пространстве в основном вытянуты вдоль прямой.
Следующее по значимости собственное значение λ2=0.921 и соответствующий
ему собственный вектор e2, вместе с вектором e1
образует двумерную плоскость.
Справа на рисунке приведена проекция данных на эту плоскость в диапазоне [-4,..,4] по каждой координате.
Вектор e1 направлен вправо, а e2 - вниз.
Статистики координат на этой плоскости имеют вид:
Главная компонента (наибольшее собственное значение λ1=2.911) cущественно отличается
от остальных. Это свидетельствует о том, что точки в 4-мерном пространстве в основном вытянуты вдоль прямой.
Следующее по значимости собственное значение λ2=0.921 и соответствующий
ему собственный вектор e2, вместе с вектором e1
образует двумерную плоскость.
Справа на рисунке приведена проекция данных на эту плоскость в диапазоне [-4,..,4] по каждой координате.
Вектор e1 направлен вправо, а e2 - вниз.
Статистики координат на этой плоскости имеют вид:
ti aver sigma min max t1 0.000 1.706 -3.298 2.765 t2 0.000 0.960 -2.713 2.649Синие круги - первый класс, красные - второй и зелёные - третий.
Пример 2: рукописные цифры MNIST
База рукописных цифр MNIST содержит содержит 60000 обучающих 10000 тестовых изображений 28x28 пикселей в градациях серого. Все картинки отцентрованы по центру тяжести и более или менее приведены к единому масштабу.

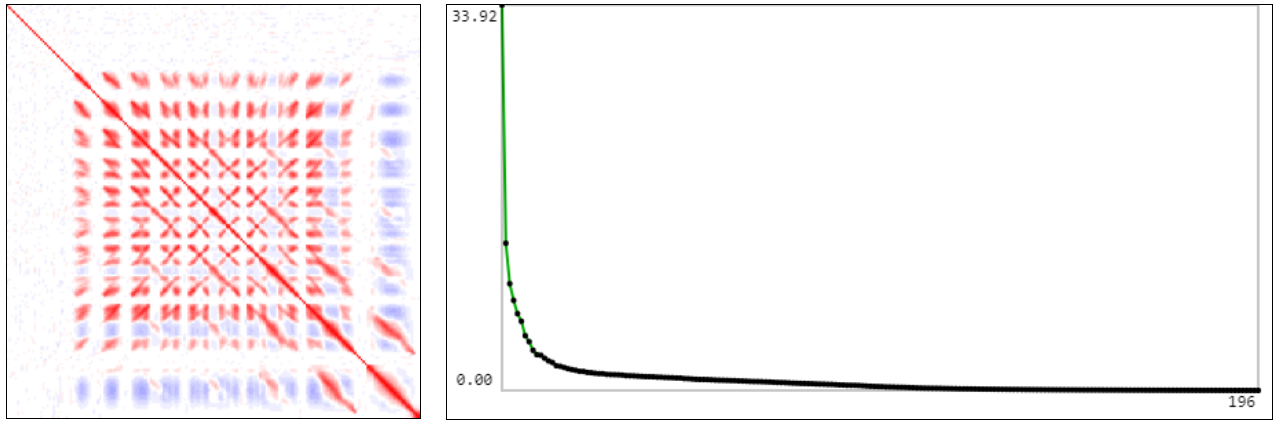
Уменьшим цифры в 2 раза (картинки 14×14) и посчитаем ковариационную матрицу (в её графическом представлении красный цвет +1, синий -1). Собственные значения ковариационной матрицы приведены справа от неё. Видно, что размерность пространства признаков существенно меньше чем 14·14=196
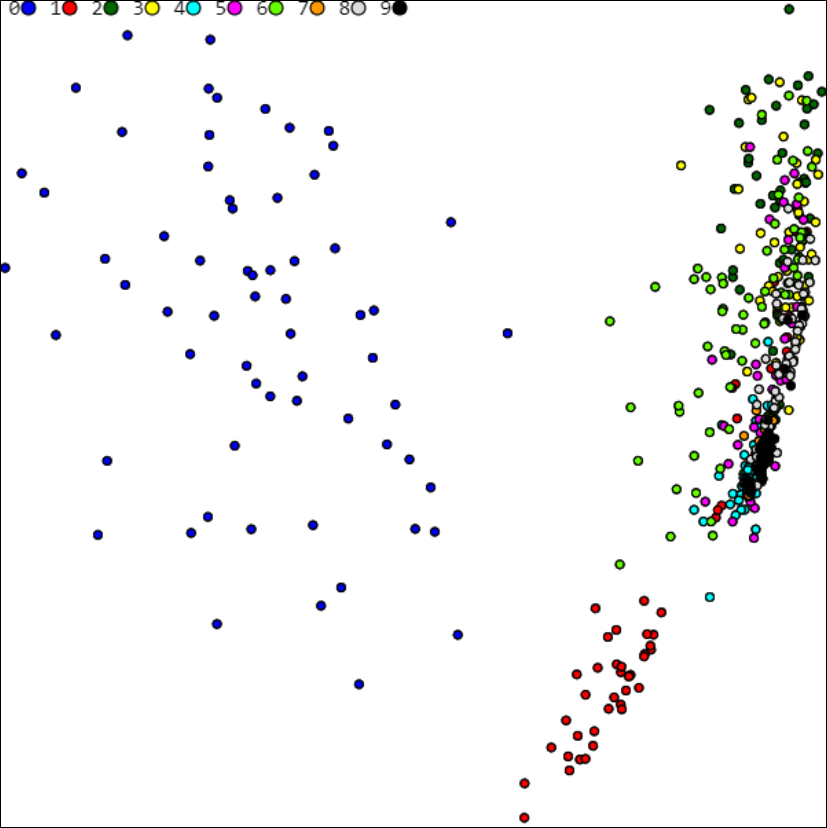
PCA 2-мерная (m=2) плоскость для MNIST имеет вид (цветом помечены различные классы=цифры, расшифровка которых приведена в верхней части рисунка):
Проблемы PCA в задачах классификации
 Метод главных компонент позволяет выяснить характерную размерность данных,
т.е. размерность поверхности, вложенной в пространство признаков.
Однако, проектирование данных на эту m-мерную плоскость может существенно
ухудшить классификацию классов.
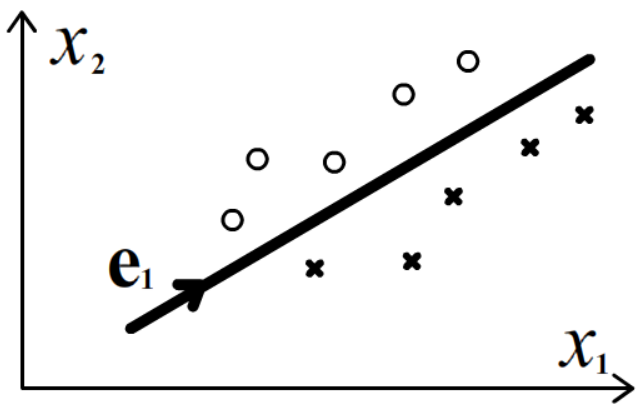
Справа на рисунке приведены два класса (круги и крестики).
Они являются хорошо (линейно) разделимыми. Однако при проектировании на линию
(одна главная компонента), объекты различных класов перемешаются и перестанут быть разделимыми.
Метод главных компонент позволяет выяснить характерную размерность данных,
т.е. размерность поверхности, вложенной в пространство признаков.
Однако, проектирование данных на эту m-мерную плоскость может существенно
ухудшить классификацию классов.
Справа на рисунке приведены два класса (круги и крестики).
Они являются хорошо (линейно) разделимыми. Однако при проектировании на линию
(одна главная компонента), объекты различных класов перемешаются и перестанут быть разделимыми.
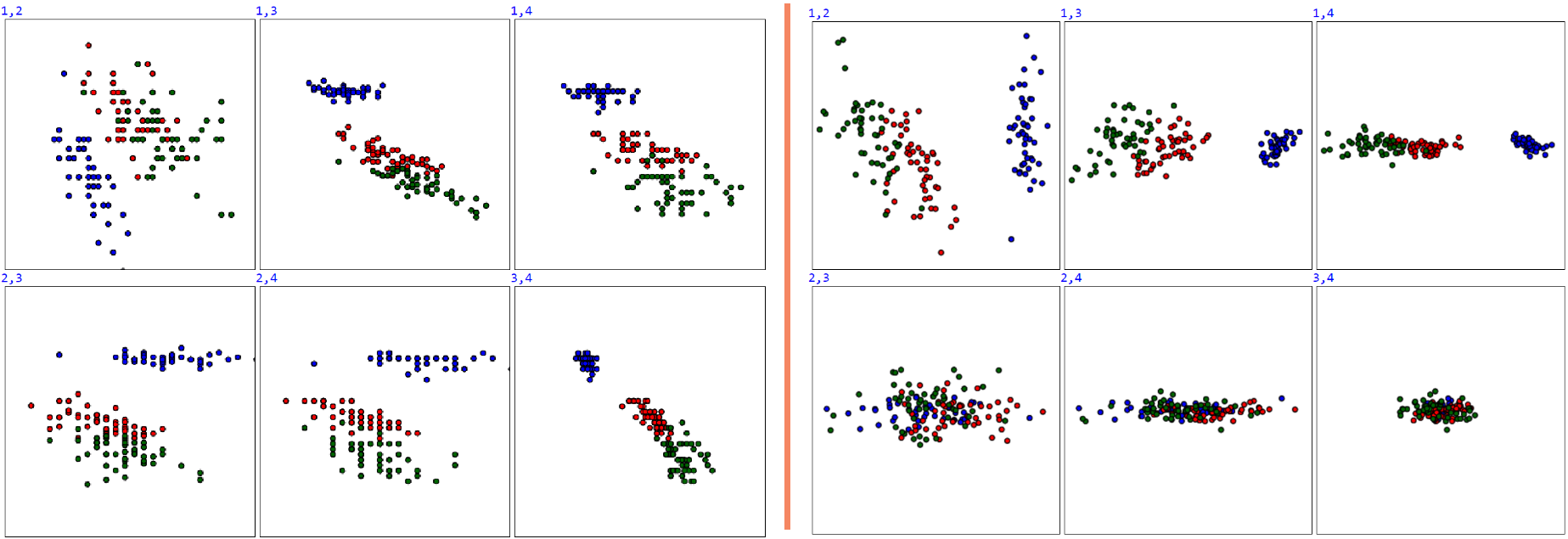
Например, в задаче ирисов Фишера метод главных компонент свидетельствует о "двумерности" исходных данных. Однако, первая главная компонента направлена не в направлении наиболее значимого (четвёртого) признака. Ниже, слева от вертикальной линии приведены исходные данные ирисов Фишера во всех парах координат. Справа те-же данные после устранения корреляции (т.е. PCA c m=4):
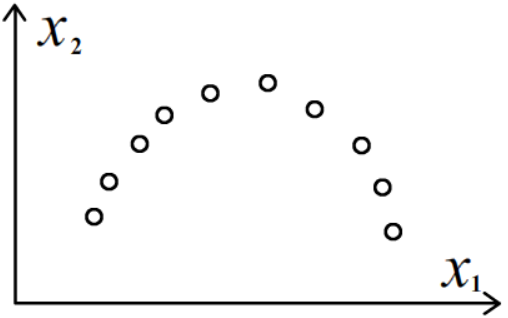 Ещё одна очевидная проблема связана с грубостью линейного приближения.
Если объекты расположены не вдоль линии или плоскости, а вдоль некой изогнутой поверхности,
метод главных компонент может вводить в заблуждение.
Ещё одна очевидная проблема связана с грубостью линейного приближения.
Если объекты расположены не вдоль линии или плоскости, а вдоль некой изогнутой поверхности,
метод главных компонент может вводить в заблуждение.