Разделяющие поверхности
Введение
Линейные решающие правила
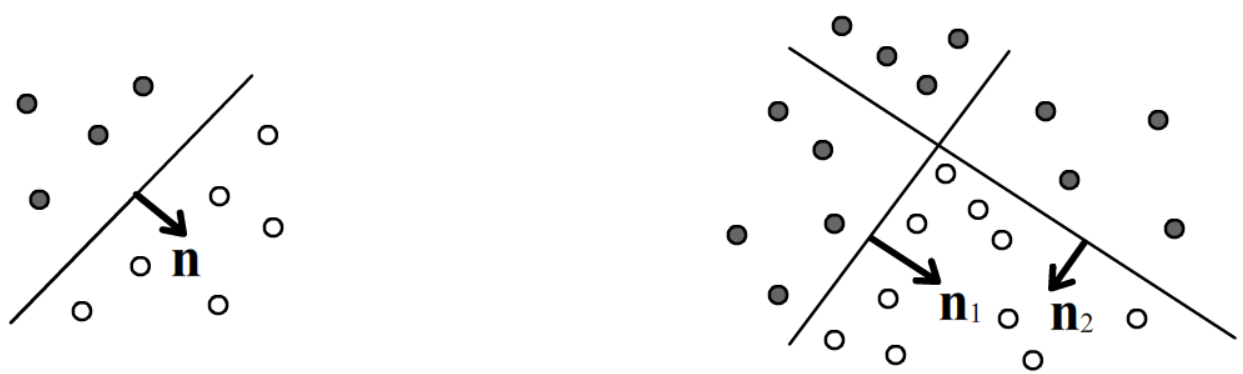
Линейные решающие правила состоят в построении гиперплоскостей в n-мерном пространстве, которые полностью разделяют примеры различных классов. Иногда бывает достаточно единственной плоскости, иногда их необходимо несколько:
Гиперплоскость, проходящая через точку x0 и имеющая единичный вектор нормали n, описывается уравнением (x−x0)⋅n=0 или nx+n0=0, где n0=−nx0. Если точка x не лежит на плоскости, то расстояние от неё до плоскости равно d=nx+n0, причём, d>0, когда точка находится с той стороны плоскости куда направлен вектор n, если d<0, то с противоположной.
На рисунках выше в первом случае решающим правилом будет d>0 для класса белых кружков и d<0 для чёрных.
Во втором случае решающее правило для чёрного класса: (d1<0 or d2<0), а
для белых: (d1>0 and d2>0), где or, and - это логические ИЛИ, И.
Заметим, что на второй картинке плоскость n1 сначала отсекает большую часть объектов чёрного класса.
После этого оставшиеся объекты двух классов уже оказываются линейно разделимыми плоскостью n2.
Дерево гиперплоскостей
Пусть в n-мерном пространстве есть два класса (или один и все остальные). Возьмём нейрон с n входами и одним выходом y=[0...1]. Проведём гиперплоскость нейрона так, чтобы сумма квадратов отклонений от неё объектов различных классов (с учётом знака расстояния) была минимальна. Кроме этого будем требовать, чтобы плоскость нейрона не уходила далеко от центра масс c всех объектов (обоих классов): Cost=1NN∑i=1(S(nxi+n0)−Yi)2+λ(n0+nc)2, где Yi={1xi∈ первый класс,0xi∈ второй класс, где S(d)=1/(1+e−d) - сигмоидная функция и λ - величина "притяжения" нейрона к центру. В соответствии с градиентным методом, необходимо подавать различные примеры xi и подправлять параметры плоскости n0,n следующим образом: n(t+1)=n(t)−γ⋅[(yi−Yi)xi+λdcc], n(t+1)0=n(t)0−γ⋅[yi−Yi+λdc], yi=S(n(t)xi+n(t)0), dc=n(t)0+n(t)c, где γ - параметр скорости обучения и отброшен "замороженный" множитель y(1−y).
Проведенная плоскость, разбивает обучающую выборку на две части. Алгоритм повторяется для каждой части, если в ней присутствуют объекты различных классов. В результате (при λ=0) получается древесное решающее правило:
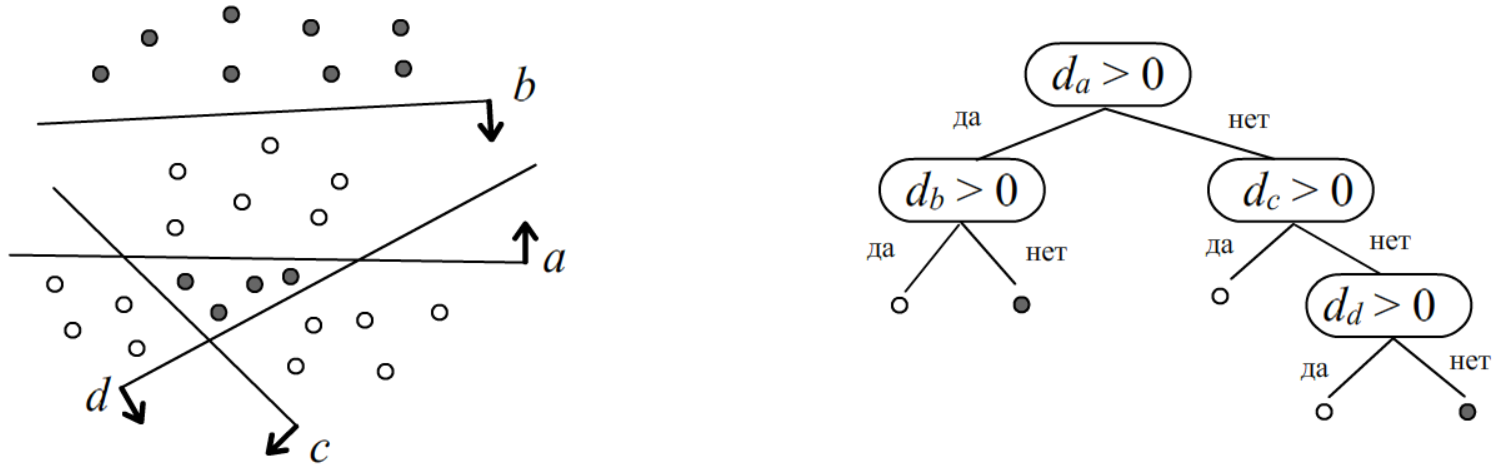
Метод опорных векторов
Если объекты двух классов линейно разделимы, между ними, вообще говоря, можно провести множество гиперплоскостей (ниже левый рисунок):
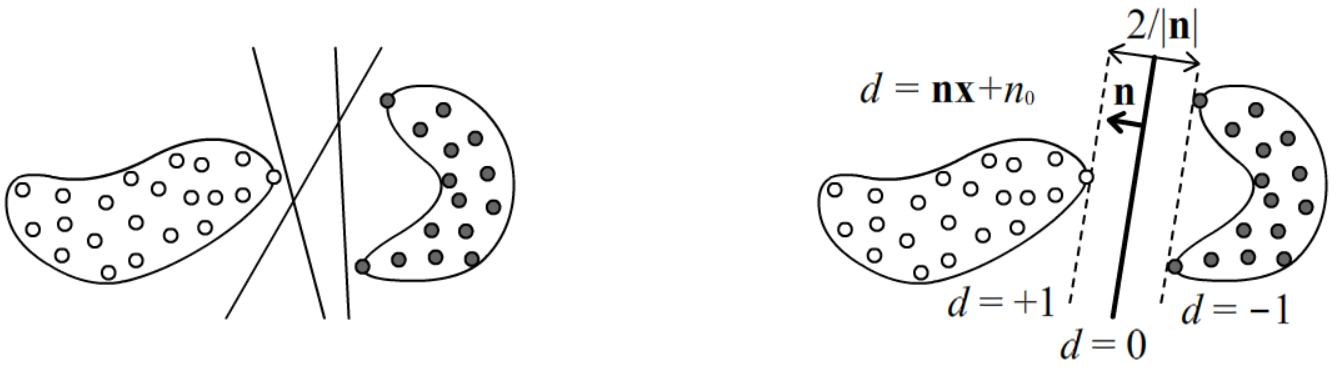
В методе опорных векторов (support vector machine, SVM) строится разделяющая классы плоскость таким образом, чтобы расстояния от неё до объектов различных классов было максимальным. Т.е. плоскость проводится так, чтобы с обоих её сторон получался максимальный зазор до примеров различных классов (выше второй рисунок).
Будем нумеровать классы Y={+1,−1} и минимизировать следующую сумму по всем примерам: Cost=N∑i=1[Ci>0], Ci(n,n0)=Yi⋅(nxi+n0), где [истина]=1, [ложь]=0, т.е. функция ошибок Cost равна числу неправильно классифицированных объектов (те, кто лежит по вектору нормали n имеют nxi+n0>0 и они верно классифицируются, если у них Yi=1, т.е. Ci(n,n0)>0; аналогично для Yi=−1). Для линейно разделимых классов существуют такие (n0,n), что для любого i=1,...,N выполняется Ci(n,n0)>0. Умножением параметров плоскости (n0,n) на общую положительную константу можно задать следующую нормировку (Cost при этом не поменяется): min В такой нормировке все объекты удовлетворяют условиям: -1 \le \mathbf{n}\mathbf{x}_i+n_0 \le +1.
Рассмотрим ближайший к плоскости пример \mathbf{x}_+ из класса Y=+1 и ближайший (с другой стороны) пример \mathbf{x}_- из класса Y=-1. По определению нормировки: \left\{ \begin{array}{ll} \mathbf{n}\mathbf{x}_+ + n_0 = +1\\ \mathbf{n}\mathbf{x}_- + n_0 = -1 \end{array} \right. ~~~~~~~\Rightarrow~~~~~~~\mathbf{n}(\mathbf{x}_+-\mathbf{x}_+) = 2. Учтём, что расстояние с не единичным вектором нормали равно d=(\mathbf{n}\mathbf{x}+n_0)/|\mathbf{n}|. Запишем суммарное расстояние до плоскости, т.е.ширину зазора 2d: 2d = d_+-d_- = \frac{\mathbf{n}\cdot(\mathbf{x}_+-\mathbf{x}_-)}{|\mathbf{n}|} = \frac{2}{|\mathbf{n}|}. Таким образом, зазор будет максимальным, если длина нормали |\mathbf{n}| минимальна при наличии ограничений (условий нормировки). В результате получается следующая оптимизационная задача: \frac{1}{2}\,\mathbf{n}^2 = \min,~~~~~~~~при~~N~~ограничениях:~~~~C_i(\mathbf{n}, n_0) \ge 1,~~~i=1,...,N.
Метод опорных векторов легко обощается на случай линейно неразделимых классов, а также на нелинейные гиперповерхности, которые называются ядрами.
Полезная информация
- [1] Воронцов К.В. ""
- Отрывок из семинара